循环神经网络(Recurrent Neural Networks) 为什么不是多层感知机(全连接前馈网络)?
多层感知机不擅长或者说不能处理可变长序列
多层感知机不能进行参数共享
为什么是循环神经网络?
Seq2Seq模型 Seq2Seq模型用来解决将可变长的输入序列映射到可变长的输出序列。这在许多场景中都有应用,如语音识别、机器翻译或问答等,其中训练集的输入序列和输出序列的长度通常不相同(虽然它们的长度可能相关)。
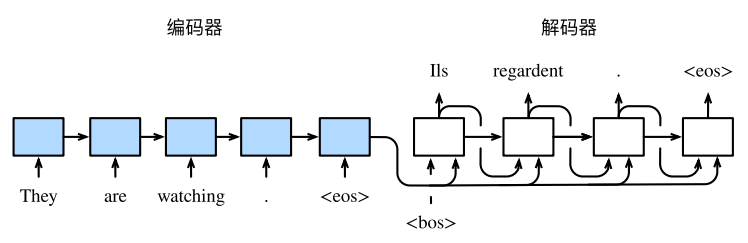
Encoder-Decoder架构 架构基本原理及组成 用于将可变长度序列映射到另一可变长度序列最简单的RNN架构是Encoder-Decoder架构。其基本思想是:编码器的每个时间步分别输入单词特征向量(采用one-hot编码或Embedding),并输出上下文向量C(通常是最终时间步的隐层状态或其简单函数),通过该向量来表征输入句子的信息。解码器在每个时间步使用上下文向量C,上一时间步输出以及上一时间步的隐层状态为输入进行预测。如下图所示为Encoder-Decoder架构示意图,其中上下文向量通常为固定长度向量。
编码器Encoder Encoder本身是一个RNN网络,RNN的单元可以是GRU,也可是LSTM。可以为单向,也可以为双向。
解码器Decoder Decoder也是一个RNN网络,其工作原理如下:对于输出序列的时间步$t{‘}$, 解码器以上一时间步的隐层状态$h_{t{‘}-1}$以及上下文向量$C$为输入,输出$y_{t{‘}}$的条件概率,即$P(y_{t{‘}}|y_1, y_2, … , y_{t{‘}-1}, C)$。
训练模型 根据极大似然估计,该问题为最优化问题,问题的目标函数为:
1 2 3 4 5 6 7 8 9 10 11 import tensorflow as tfimport matplotlib as mplimport matplotlib.pyplot as plt%matplotlib inline import numpy as npimport sklearnimport pandas as pdimport osimport sysimport timefrom tensorflow import keras
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 en_spa_file_path = './data_spa_en/spa.txt' import unicodedatadef unicode_to_ascii (s) : '''西班牙语中的特殊字符是使用UNICODE表示的,需要转换成ASCII码。转换成ASCII后,vocabe_size=128 or 256''' return '' .join(c for c in unicodedata.normalize('NFD' , s) if unicodedata.category(c) != 'Mn' ) en_sentence = 'Then what?' sp_sentence = '¿Entonces qué?' print(unicode_to_ascii(en_sentence)) print(unicode_to_ascii(sp_sentence))
Then what?
¿Entonces que?1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import redef preprocess_sentence (s) : s = unicode_to_ascii(s.lower().strip()) s = re.sub(r"([?.!,¿])" , r" \1 " , s) s = re.sub(r'[" "]+' , " " , s) s = re.sub(r'[^a-zA-Z?.!,¿]' , " " , s) s = s.rstrip().strip() s = '<start> ' + s + ' <end>' return s print(preprocess_sentence(en_sentence)) print(preprocess_sentence(sp_sentence))
<start> then what ? <end>
<start> ¿ entonces que ? <end>1 2 3 4 5 6 7 8 9 10 11 12 def parse_data (filename) : lines = open(filename, encoding='UTF-8' ).read().strip().split('\n' ) sentence_pairs = [line.split('\t' ) for line in lines] preprocessed_sentence_pairs = [(preprocess_sentence(en), preprocess_sentence(sp)) for [en, sp] in sentence_pairs] return zip(*preprocessed_sentence_pairs) en_dataset, sp_dataset = parse_data(en_spa_file_path) print(en_dataset[-1 ]) print(sp_dataset[-1 ])
<start> if you want to sound like a native speaker , you must be willing to practice saying the same sentence over and over in the same way that banjo players practice the same phrase over and over until they can play it correctly and at the desired tempo . <end>
<start> si quieres sonar como un hablante nativo , debes estar dispuesto a practicar diciendo la misma frase una y otra vez de la misma manera en que un musico de banjo practica el mismo fraseo una y otra vez hasta que lo puedan tocar correctamente y en el tiempo esperado . <end>1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 def tokenizer (lang) : lang_tokenizer = keras.preprocessing.text.Tokenizer(num_words=None , filters='' , split=' ' ) lang_tokenizer.fit_on_texts(lang) tensor = lang_tokenizer.texts_to_sequences(lang) tensor = keras.preprocessing.sequence.pad_sequences(tensor, padding='post' ) return tensor, lang_tokenizer input_tensor, input_tokenizer = tokenizer(sp_dataset[0 :30000 ]) print(input_tensor.shape) output_tensor, output_tokenizer = tokenizer(en_dataset[0 :30000 ]) def max_length (tensor) : return max(len(t) for t in tensor) max_length_input = max_length(input_tensor) max_length_output = max_length(output_tensor) print(max_length_input, max_length_output)
(30000, 16)
16 111 2 3 4 from sklearn.model_selection import train_test_splitinput_train, input_eval, output_train, output_eval = train_test_split( input_tensor, output_tensor, test_size=0.2 ) len(input_train), len(input_eval), len(output_train), len(output_eval)
(24000, 6000, 24000, 6000)1 2 3 4 5 6 7 8 9 def convert (example, tokenizer) : for t in example: if t != 0 : print('%d --> %s' % (t, tokenizer.index_word[t])) convert(input_train[0 ], input_tokenizer) print() convert(output_train[0 ], output_tokenizer)
1 --> <start>
26 --> yo
160 --> tenia
239 --> anos
20 --> en
3 --> .
2 --> <end>
1 --> <start>
4 --> i
26 --> was
33 --> in
3 --> .
2 --> <end>1 2 3 4 5 6 7 8 9 10 11 12 13 def make_dataset (input_tensor, output_tensor, batch_size, epochs, shuffle) : dataset = tf.data.Dataset.from_tensor_slices((input_tensor, output_tensor)) if shuffle: dataset = dataset.shuffle(30000 ) dataset = dataset.repeat(epochs).batch(batch_size, drop_remainder=True ) return dataset batch_size = 64 epochs = 20 train_dataset = make_dataset(input_train, output_train, batch_size, epochs, True ) eval_dataset = make_dataset(input_eval, output_eval, batch_size, 1 , False )
1 2 3 4 5 for x, y in train_dataset.take(1 ): print(x.shape) print(y.shape) print(x) print(y)
(64, 16)
(64, 11)
tf.Tensor(
[[ 1 7824 13 ... 0 0 0]
[ 1 6 11 ... 0 0 0]
[ 1 6 14 ... 0 0 0]
...
[ 1 137 497 ... 0 0 0]
[ 1 12 597 ... 0 0 0]
[ 1 16 7 ... 0 0 0]], shape=(64, 16), dtype=int32)
tf.Tensor(
[[ 1 116 126 13 465 3 2 0 0 0 0]
[ 1 32 2077 20 7 2 0 0 0 0 0]
[ 1 32 1779 8 10 7 2 0 0 0 0]
[ 1 8 5 3258 7 2 0 0 0 0 0]
[ 1 199 140 657 44 3 2 0 0 0 0]
[ 1 4 18 85 473 3 2 0 0 0 0]
[ 1 28 233 33 1853 3 2 0 0 0 0]
[ 1 4 25 2415 68 3 2 0 0 0 0]
[ 1 14 42 9 69 134 3 2 0 0 0]
[ 1 16 262 6 3 2 0 0 0 0 0]
[ 1 14 11 9 443 159 3 2 0 0 0]
[ 1 21 165 919 8 3 2 0 0 0 0]
[ 1 4 1250 1111 3 2 0 0 0 0 0]
[ 1 56 185 13 201 3 2 0 0 0 0]
[ 1 992 8 9 4415 3 2 0 0 0 0]
[ 1 5 1360 596 265 3 2 0 0 0 0]
[ 1 6 23 35 17 3 2 0 0 0 0]
[ 1 4 135 1773 3 2 0 0 0 0 0]
[ 1 5 825 9 578 3 2 0 0 0 0]
[ 1 4 62 884 376 3 2 0 0 0 0]
[ 1 30 12 456 31 837 3 2 0 0 0]
[ 1 46 11 279 15 544 3 2 0 0 0]
[ 1 71 8 31 168 7 2 0 0 0 0]
[ 1 4 18 537 4 169 73 3 2 0 0]
[ 1 25 6 2944 20 7 2 0 0 0 0]
[ 1 4 29 2329 59 97 3 2 0 0 0]
[ 1 4 29 66 493 3 2 0 0 0 0]
[ 1 10 11 69 15 40 89 3 2 0 0]
[ 1 14 87 12 72 486 3 2 0 0 0]
[ 1 32 11 13 1108 7 2 0 0 0 0]
[ 1 6 92 348 3 2 0 0 0 0 0]
[ 1 441 16 25 149 3 2 0 0 0 0]
[ 1 22 6 35 1856 7 2 0 0 0 0]
[ 1 4 43 126 67 3 2 0 0 0 0]
[ 1 5 26 624 50 3 2 0 0 0 0]
[ 1 5 905 54 73 3 2 0 0 0 0]
[ 1 22 6 103 63 383 7 2 0 0 0]
[ 1 42 6 202 242 7 2 0 0 0 0]
[ 1 27 11 9 421 2264 3 2 0 0 0]
[ 1 271 6 35 9 104 7 2 0 0 0]
[ 1 5 8 1046 3 2 0 0 0 0 0]
[ 1 24 31 344 438 7 2 0 0 0 0]
[ 1 32 271 5 47 7 2 0 0 0 0]
[ 1 60 1206 6 7 2 0 0 0 0 0]
[ 1 4 472 417 9 1227 3 2 0 0 0]
[ 1 6 25 12 302 17 3 2 0 0 0]
[ 1 4 25 12 64 197 10 3 2 0 0]
[ 1 4 65 105 21 2271 3 2 0 0 0]
[ 1 16 65 160 4279 3 2 0 0 0 0]
[ 1 32 478 717 7 2 0 0 0 0 0]
[ 1 755 496 3 2 0 0 0 0 0 0]
[ 1 6 24 85 273 3 2 0 0 0 0]
[ 1 5 872 319 3 2 0 0 0 0 0]
[ 1 9 728 8 9 728 3 2 0 0 0]
[ 1 5 411 1522 3 2 0 0 0 0 0]
[ 1 28 42 10 3 2 0 0 0 0 0]
[ 1 25 4 125 10 44 7 2 0 0 0]
[ 1 28 23 649 3 2 0 0 0 0 0]
[ 1 13 850 92 293 3 2 0 0 0 0]
[ 1 4 30 12 510 43 3 2 0 0 0]
[ 1 4 18 34 2363 3 2 0 0 0 0]
[ 1 379 1020 3 2 0 0 0 0 0 0]
[ 1 10 11 21 205 3 2 0 0 0 0]
[ 1 19 8 31 385 3 2 0 0 0 0]], shape=(64, 11), dtype=int32)1 2 3 4 5 embedding_units = 256 units = 1024 input_vocab_size = len(input_tokenizer.word_index) + 1 output_vocab_size = len(output_tokenizer.word_index) + 1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class Encoder (keras.Model) : def __init__ (self, vocab_size, embedding_units, encoding_units, batch_size) : super(Encoder, self).__init__() self.batch_size = batch_size self.encoding_units = encoding_units self.embedding = keras.layers.Embedding(vocab_size, embedding_units) self.gru = keras.layers.GRU(self.encoding_units, return_sequences=True , return_state=True , recurrent_initializer='glorot_uniform' ) def call (self, x, hidden) : x = self.embedding(x) output, state = self.gru(x, initial_state=hidden) return output, state def initialize_hidden_state (self) : '''创建一个全是0的隐含状态,传给call函数''' return tf.zeros((self.batch_size, self.encoding_units)) encoder = Encoder(input_vocab_size, embedding_units, units, batch_size) sample_hidden = encoder.initialize_hidden_state() sample_output, sample_hidden = encoder(x, sample_hidden) print("sample_output_shape" , sample_output.shape) print("sample_hidden_shape" , sample_hidden.shape)
sample_output_shape (64, 16, 1024)
sample_hidden_shape (64, 1024)1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class BahdananAttention (keras.Model) : def __init__ (self, units) : super(BahdananAttention, self).__init__() self.W1 = keras.layers.Dense(units) self.W2 = keras.layers.Dense(units) self.V = keras.layers.Dense(1 ) def call (self, decoder_hidden, encoder_outputs) : """decoder_hidden:decoder某一时间步的隐层状态,encoder_output:encoder每一时间步的输出""" decoder_hidden_with_time_axis = tf.expand_dims(decoder_hidden, axis=1 ) score = self.V( tf.nn.tanh(self.W1(encoder_outputs) + self.W2(decoder_hidden_with_time_axis))) attention_weights = tf.nn.softmax(score, axis=1 ) context_vector = attention_weights * encoder_outputs context_vector = tf.reduce_sum(context_vector, axis=1 ) return context_vector, attention_weights
1 2 3 4 5 attention_model = BahdananAttention(units = 10 ) attention_results, attention_weights = attention_model(sample_hidden, sample_output) print("attention_results.shape:" , attention_results.shape) print("attention_weights.shape:" , attention_weights.shape)
attention_results.shape: (64, 1024)
attention_weights.shape: (64, 16, 1)1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 class Decoder (keras.Model) : def __init__ (self, vocab_size, embedding_units, decoding_units, batch_size) : super(Decoder, self).__init__() self.batch_size = batch_size self.decoding_units = decoding_units self.embedding = keras.layers.Embedding(vocab_size, embedding_units) self.gru = keras.layers.GRU(self.decoding_units, return_sequences=True , return_state=True , recurrent_initializer='glorot_uniform' ) self.fc = keras.layers.Dense(vocab_size) self.attention = BahdananAttention(self.decoding_units) def call (self, x, hidden, encoding_outputs) : ''' x: decoder 当前步的输入 hidden: 上一步的隐层状态 encoding_outputs: 经过注意力向量加权求和后的上下文向量 ''' context_vector, attention_weights = self.attention( hidden, encoding_outputs) x = self.embedding(x) combined_x = tf.concat([tf.expand_dims(context_vector, 1 ), x], axis=-1 ) output, state = self.gru(combined_x) output = tf.reshape(output, (-1 , output.shape[2 ])) output = self.fc(output) return output, state, attention_weights decoder = Decoder(output_vocab_size, embedding_units, units, batch_size) outputs = decoder(tf.random.uniform((batch_size, 1 )), sample_hidden, sample_output) decoder_output, decoder_hidden, decoder_aw = outputs print(decoder_output.shape) print(decoder_hidden.shape) print(decoder_aw.shape)
(64, 4935)
(64, 1024)
(64, 16, 1)1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 optimizer = keras.optimizers.Adam() loss_object = keras.losses.SparseCategoricalCrossentropy(from_logits=True , reduction='none' ) def loss_function (real, pred) : mask = tf.math.logical_not(tf.math.equal(real, 0 )) loss_ = loss_object(real, pred) mask = tf.cast(mask, dtype=loss_.dtype) loss_ *= mask return tf.reduce_mean(loss_)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 @tf.function def train_step (inp, targ, encoding_hidden) : loss = 0 with tf.GradientTape() as tape: encoding_outputs, encoding_hidden = encoder(inp, encoding_hidden) decoding_hidden = encoding_hidden for t in range(0 , targ.shape[1 ] - 1 ): decoding_input = tf.expand_dims(targ[:, t], 1 ) predictions, decoding_hidden, _ = decoder(decoding_input, decoding_hidden, encoding_outputs) loss += loss_function(targ[:, t + 1 ], predictions) batch_loss = loss / int(targ.shape[0 ]) variables = encoder.trainable_variables + decoder.trainable_variables gradients = tape.gradient(loss, variables) optimizer.apply_gradients(zip(gradients, variables)) return batch_loss
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 epochs = 10 steps_per_epoch = len(input_tensor) // batch_size for epoch in range(epochs): start = time.time() encoding_hidden = encoder.initialize_hidden_state() total_loss = 0 for (batch, (inp, targ)) in enumerate(train_dataset.take(steps_per_epoch)): '''从训练集中取出steps_per_epoch个batch的数据''' batch_loss = train_step(inp, targ, encoding_hidden) total_loss += batch_loss if batch % 100 == 0 : '''每100个batch打印一次数据:Batch从0索引,Epoch从1索引,batch_loss是平均到每条样本上的loss''' print('Epoch {} Batch {} Loss {:.4f}' .format( epoch + 1 , batch, batch_loss.numpy())) '''每遍历一个epoch后打印一次信息:其中Loss保留小数点后四位,/steps_per_epoch后为每条样本的平均误差''' print('Epoch {} Loss {:.4f}' .format(epoch + 1 , total_loss / steps_per_epoch)) print('Time take 1 epoch {} sec\n' .format(time.time() - start))
Epoch 1 Batch 0 Loss 0.8035
Epoch 1 Batch 100 Loss 0.3535
Epoch 1 Batch 200 Loss 0.3359
Epoch 1 Batch 300 Loss 0.2851
Epoch 1 Batch 400 Loss 0.2671
Epoch 1 Loss 0.3293
Time take 1 epoch 2116.8650002479553 sec
Epoch 2 Batch 0 Loss 0.2466
Epoch 2 Batch 100 Loss 0.2326
Epoch 2 Batch 200 Loss 0.2236
Epoch 2 Batch 300 Loss 0.2260
Epoch 2 Batch 400 Loss 0.1522
Epoch 2 Loss 0.2067
Time take 1 epoch 2149.2449696063995 sec
Epoch 3 Batch 0 Loss 0.1331
Epoch 3 Batch 100 Loss 0.1548
Epoch 3 Batch 200 Loss 0.1314
Epoch 3 Batch 300 Loss 0.1256
Epoch 3 Batch 400 Loss 0.0868
Epoch 3 Loss 0.1272
Time take 1 epoch 2136.0347578525543 sec
Epoch 4 Batch 0 Loss 0.0693
Epoch 4 Batch 100 Loss 0.0904
Epoch 4 Batch 200 Loss 0.0876
Epoch 4 Batch 300 Loss 0.0791
Epoch 4 Batch 400 Loss 0.0469
Epoch 4 Loss 0.0776
Time take 1 epoch 2133.8691380023956 sec
Epoch 5 Batch 0 Loss 0.0511
Epoch 5 Batch 100 Loss 0.0523
Epoch 5 Batch 200 Loss 0.0537
Epoch 5 Batch 300 Loss 0.0500
Epoch 5 Batch 400 Loss 0.0347
Epoch 5 Loss 0.0483
Time take 1 epoch 2115.8476724624634 sec
Epoch 6 Batch 0 Loss 0.0240
Epoch 6 Batch 100 Loss 0.0340
Epoch 6 Batch 200 Loss 0.0424
Epoch 6 Batch 300 Loss 0.0272
Epoch 6 Batch 400 Loss 0.0157
Epoch 6 Loss 0.0319
Time take 1 epoch 2182.366710424423 sec
Epoch 7 Batch 0 Loss 0.0208
Epoch 7 Batch 100 Loss 0.0224
Epoch 7 Batch 200 Loss 0.0275
Epoch 7 Batch 300 Loss 0.0247
Epoch 7 Batch 400 Loss 0.0153
Epoch 7 Loss 0.0224
Time take 1 epoch 2116.347582578659 sec
Epoch 8 Batch 0 Loss 0.0180
Epoch 8 Batch 100 Loss 0.0161
Epoch 8 Batch 200 Loss 0.0209
Epoch 8 Batch 300 Loss 0.0178
Epoch 8 Batch 400 Loss 0.0154
Epoch 8 Loss 0.0170
Time take 1 epoch 2139.7361178398132 sec
Epoch 9 Batch 0 Loss 0.0099
Epoch 9 Batch 100 Loss 0.0096
Epoch 9 Batch 200 Loss 0.0128
Epoch 9 Batch 300 Loss 0.0173
Epoch 9 Batch 400 Loss 0.0094
Epoch 9 Loss 0.0136
Time take 1 epoch 2131.8980412483215 sec
Epoch 10 Batch 0 Loss 0.0096
Epoch 10 Batch 100 Loss 0.0076
Epoch 10 Batch 200 Loss 0.0135
Epoch 10 Batch 300 Loss 0.0100
Epoch 10 Batch 400 Loss 0.0089
Epoch 10 Loss 0.0123
Time take 1 epoch 2125.301104068756 sec1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 def evaluate (input_sentence) : attention_matrix = np.zeros((max_length_output, max_length_input)) input_sentence = preprocess_sentence(input_sentence) inputs = [ input_tokenizer.word_index[token] for token in input_sentence.split(' ' ) ] inputs = keras.preprocessing.sequence.pad_sequences( [inputs], maxlen=max_length_input, padding='post' ) inputs = tf.convert_to_tensor(inputs) results = ' ' encoding_hidden = tf.zeros((1 , units)) encoding_outputs, encoding_hidden = encoder(inputs, encoding_hidden) decoding_hidden = encoding_hidden decoding_input = tf.expand_dims([output_tokenizer.word_index['<start>' ]], 0 ) for t in range(max_length_output): predictions, decoding_hidden, attention_weights = decoder( decoding_input, decoding_hidden, encoding_outputs) attention_weights = tf.reshape(attention_weights, (-1 , )) attention_matrix[t] = attention_weights.numpy() predicted_id = tf.argmax(predictions[0 ]).numpy() results += output_tokenizer.index_word[predicted_id] + " " if output_tokenizer.index_word[predicted_id] == '<end>' : return results, input_sentence, attention_matrix decoding_input = tf.expand_dims([predicted_id], 0 ) return results, input_sentence, attention_matrix def plot_attention (attention_matrix, input_sentence, predicted_sentence) : fig = plt.figure(figsize=(10 , 10 )) ax = fig.add_subplot(1 , 1 , 1 ) ax.matshow(attention_matrix, cmap='viridis' ) font_dict = {'fontsize' : 14 } ax.set_xticklabels([' ' ] + input_sentence, fontdict=font_dict, rotation=90 ) ax.set_yticklabels([' ' ] + predicted_sentence, fontdict=font_dict) plt.show() def translate (input_sentence) : results, input_sentence, attention_matrix = evaluate(input_sentence) print("Input: %s" % (input_sentence)) print("Predicted translation: %s" % (results)) attention_matrix = attention_matrix[:len(results.split(' ' )), :len( input_sentence.split(' ' ))] plot_attention(attention_matrix, input_sentence.split(' ' ), results.split(' ' ))
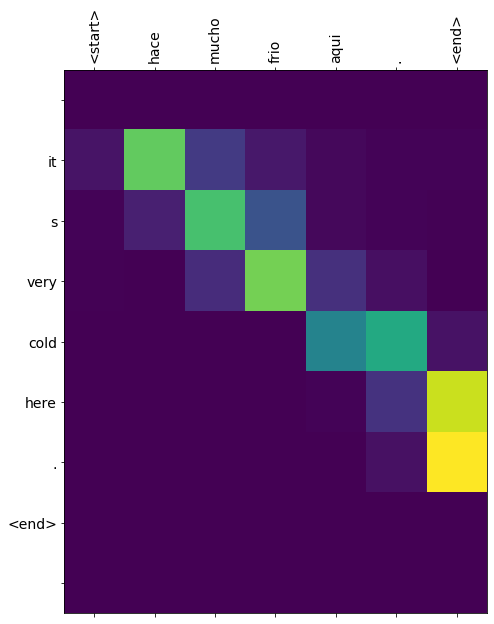
1 translate(u'Hace mucho frío aquí.' )
Input: <start> hace mucho frio aqui . <end>
Predicted translation: it s very cold here . <end>
1 translate(u'Esta es mi vida.' )
Input: <start> esta es mi vida . <end>
Predicted translation: this is my life . <end>
1 translate(u'¿Todavía estás en casa?' )
Input: <start> ¿ todavia estas en casa ? <end>
Predicted translation: are you still at home ? <end>