基于attention的seq2seq
去除定长编码瓶颈, 信息无损从Encoder传到Decoder
但是
采用GRU, 计算仍然有瓶颈, 并行度不高(计算时存在相互依赖,不管是Encoder还是Decoder,在处理seq时都是从前到后的处理模式,前面的词没有处理完,后面的词不能进行处理,并行度不高)
只有Encoder和Decoder之间有attention(Encoder和Decoder之间存在attention, 但是Encoder和Decoder自身不存在attention,这里可以将attention理解为一种无损的信息传递机制,如果Encoder不同时间步之间不存在attention机制,则只能通过GRU或LSTM的隐含状态进行信息传递,但是这种信息传递的机制在序列长度较长时会产生信息损失)
能否去掉RNN? 能
能够给输入输出分别加上self attention? 能
参考博客:图解Transformer
Encoder-Decoder架构
多层Encoder-Decoder
位置编码
多头注意力
Add & Norm
代码实战 参考视频:Tensorflow2.0入门到进阶
1 2 3 4 5 6 7 8 9 10 11 import tensorflow as tfimport matplotlib as mplimport matplotlib.pyplot as plt%matplotlib inline import numpy as npimport sklearnimport pandas as pdimport osimport sysimport timefrom tensorflow import keras
1 2 3 4 5 6 import tensorflow_datasets as tfdsexamples, info = tfds.load('ted_hrlr_translate/pt_to_en' , with_info=True , as_supervised=True ) train_examples, val_examples = examples['train' ], examples['validation' ] print(info)
tfds.core.DatasetInfo(
name='ted_hrlr_translate',
version=1.0.0,
description='Data sets derived from TED talk transcripts for comparing similar language pairs
where one is high resource and the other is low resource.',
homepage='https://github.com/neulab/word-embeddings-for-nmt',
features=Translation({
'en': Text(shape=(), dtype=tf.string),
'pt': Text(shape=(), dtype=tf.string),
}),
total_num_examples=54781,
splits={
'test': 1803,
'train': 51785,
'validation': 1193,
},
supervised_keys=('pt', 'en'),
citation="""@inproceedings{Ye2018WordEmbeddings,
author = {Ye, Qi and Devendra, Sachan and Matthieu, Felix and Sarguna, Padmanabhan and Graham, Neubig},
title = {When and Why are pre-trained word embeddings useful for Neural Machine Translation},
booktitle = {HLT-NAACL},
year = {2018},
}""",
redistribution_info=,
)1 2 3 4 for pt, en in train_examples.take(5 ): print(pt.numpy()) print(en.numpy()) print()
b'e quando melhoramos a procura , tiramos a \xc3\xbanica vantagem da impress\xc3\xa3o , que \xc3\xa9 a serendipidade .'
b'and when you improve searchability , you actually take away the one advantage of print , which is serendipity .'
b'mas e se estes fatores fossem ativos ?'
b'but what if it were active ?'
b'mas eles n\xc3\xa3o tinham a curiosidade de me testar .'
b"but they did n't test for curiosity ."
b'e esta rebeldia consciente \xc3\xa9 a raz\xc3\xa3o pela qual eu , como agn\xc3\xb3stica , posso ainda ter f\xc3\xa9 .'
b'and this conscious defiance is why i , as an agnostic , can still have faith .'
b"`` `` '' podem usar tudo sobre a mesa no meu corpo . ''"
b'you can use everything on the table on me .'1 2 3 4 5 en_tokenizer = tfds.features.text.SubwordTextEncoder.build_from_corpus( (en.numpy() for pt, en in train_examples), target_vocab_size=2 **13 ) pt_tokenizer = tfds.features.text.SubwordTextEncoder.build_from_corpus( (pt.numpy() for pt, en in train_examples), target_vocab_size=2 **13 )
1 2 3 4 5 6 7 8 9 10 11 12 sample_string = "Transformer is awesome." tokenized_string = en_tokenizer.encode(sample_string) print("Tokenized string is {}" .format(tokenized_string)) origin_string = en_tokenizer.decode(tokenized_string) print("The original string is {}" .format(origin_string)) assert origin_string == sample_stringfor token in tokenized_string: print('{} --> "{}"' .format(token, en_tokenizer.decode([token])))
Tokenized string is [7915, 1248, 7946, 7194, 13, 2799, 7877]
The original string is Transformer is awesome.
7915 --> "T"
1248 --> "ran"
7946 --> "s"
7194 --> "former "
13 --> "is "
2799 --> "awesome"
7877 --> "."1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 buffer_size = 20000 batch_size = 64 max_length = 40 def encode_to_subword (pt_sentence, en_sentence) : '''使用词表将西班牙语和英语的句子对映射为整数列表''' pt_sequence = [pt_tokenizer.vocab_size] + \ pt_tokenizer.encode(pt_sentence.numpy()) + \ [pt_tokenizer.vocab_size + 1 ] en_sequence = [en_tokenizer.vocab_size] + \ en_tokenizer.encode(en_sentence.numpy()) + \ [en_tokenizer.vocab_size + 1 ] return pt_sequence, en_sequence def filter_by_max_length (pt, en) : return tf.logical_and(tf.size(pt) <= max_length, tf.size(en) <= max_length) def tf_encode_to_subword (pt_sentence, en_sentence) : return tf.py_function(encode_to_subword, [pt_sentence, en_sentence], [tf.int64, tf.int64]) train_dataset = train_examples.map(tf_encode_to_subword) train_dataset = train_dataset.filter(filter_by_max_length) train_dataset = train_dataset.shuffle(buffer_size).padded_batch( batch_size, padded_shapes=([-1 ], [-1 ])) valid_dataset = val_examples.map(tf_encode_to_subword) valid_dataset = valid_dataset.filter(filter_by_max_length) valid_dataset = valid_dataset.shuffle(buffer_size).padded_batch( batch_size, padded_shapes=([-1 ], [-1 ]))
1 2 for pt_batch, en_batch in valid_dataset.take(5 ): print(pt_batch.shape, en_batch.shape)
(64, 32) (64, 34)
(64, 40) (64, 35)
(64, 39) (64, 39)
(64, 37) (64, 35)
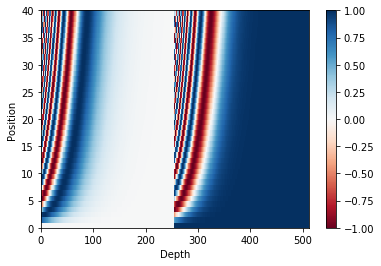
(64, 40) (64, 39)1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 def get_angles (pos, i, d_model) : angle_rates = 1 / np.power( 10000 , (2 * (i // 2 )) / np.float32(d_model)) return pos * angle_rates def get_position_embedding (sentence_length, d_model) : angle_rads = get_angles( np.arange(sentence_length)[:, np.newaxis], np.arange(d_model)[np.newaxis, :], d_model) sines = np.sin(angle_rads[:, 0 ::2 ]) cosines = np.cos(angle_rads[:, 1 ::2 ]) position_embedding = np.concatenate([sines, cosines], axis=-1 ) position_embedding = position_embedding[np.newaxis, ...] return tf.cast(position_embedding, dtype=tf.float32) position_embedding = get_position_embedding(40 , 512 ) print(position_embedding.shape)
(1, 40, 512)1 2 3 4 5 6 7 8 9 10 def plot_position_embedding (position_embedding) : plt.pcolormesh(position_embedding[0 ], cmap='RdBu' ) plt.xlabel('Depth' ) plt.xlim((0 , 512 )) plt.ylabel('Position' ) plt.colorbar() plt.show() plot_position_embedding(position_embedding)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def create_padding_mask (batch_data) : padding_mask = tf.cast(tf.math.equal(batch_data, 0 ), tf.float32) return padding_mask[:, tf.newaxis, tf.newaxis, :] x = tf.constant([[7 , 6 , 0 , 0 , 1 ], [1 , 2 , 3 , 0 , 0 ], [0 , 0 , 0 , 4 , 5 ]]) print(x) create_padding_mask(x)
tf.Tensor(
[[7 6 0 0 1]
[1 2 3 0 0]
[0 0 0 4 5]], shape=(3, 5), dtype=int32)
<tf.Tensor: shape=(3, 1, 1, 5), dtype=float32, numpy=
array([[[[0., 0., 1., 1., 0.]]],
[[[0., 0., 0., 1., 1.]]],
[[[1., 1., 1., 0., 0.]]]], dtype=float32)>1 2 3 4 5 6 7 8 9 10 def create_look_ahead_mask (size) : mask = 1 - tf.linalg.band_part(tf.ones((size, size)), -1 , 0 ) return mask create_look_ahead_mask(3 )
<tf.Tensor: shape=(3, 3), dtype=float32, numpy=
array([[0., 1., 1.],
[0., 0., 1.],
[0., 0., 0.]], dtype=float32)>1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 def scaled_dot_product_attention (q, k, v, mask) : """ Args: - q: shape == (..., seq_len_q, depth) - k: shape == (..., seq_len_k, depth) - v: shape == (..., seq_len_v, depth_v) - seq_len_k == seq_len_v - mask: shape == (..., seq_len_q, seq_len_k) Returns: - output: weighted sum - attention_weights: weights of attention """ matmul_qk = tf.matmul(q, k, transpose_b=True ) dk = tf.cast(tf.shape(k)[-1 ], tf.float32) scaled_attention_logits = matmul_qk / tf.math.sqrt(dk) if mask is not None : scaled_attention_logits += (mask * -1e9 ) attention_weights = tf.nn.softmax(scaled_attention_logits, axis=-1 ) output = tf.matmul(attention_weights, v) return output, attention_weights def print_scaled_dot_product_attention (q, k, v) : temp_out, temp_att = scaled_dot_product_attention(q, k, v, None ) print("Attention weights are:" ) print(temp_att) print("Output is:" ) print(temp_out)
1 2 3 4 5 6 7 temp_k = tf.constant([[10 , 0 , 0 ], [0 , 10 , 0 ], [0 , 0 , 10 ], [0 , 0 , 10 ]], dtype=tf.float32) temp_v = tf.constant([[1 , 0 ], [10 , 0 ], [100 , 5 ], [1000 , 6 ]], dtype=tf.float32) temp_q1 = tf.constant([[0 , 10 , 0 ]], dtype=tf.float32) np.set_printoptions(suppress=True ) print_scaled_dot_product_attention(temp_q1, temp_k, temp_v)
Attention weights are:
tf.Tensor([[0. 1. 0. 0.]], shape=(1, 4), dtype=float32)
Output is:
tf.Tensor([[10. 0.]], shape=(1, 2), dtype=float32)1 2 temp_q2 = tf.constant([[0 , 0 , 10 ]], dtype=tf.float32) print_scaled_dot_product_attention(temp_q2, temp_k, temp_v)
Attention weights are:
tf.Tensor([[0. 0. 0.5 0.5]], shape=(1, 4), dtype=float32)
Output is:
tf.Tensor([[550. 5.5]], shape=(1, 2), dtype=float32)1 2 temp_q3 = tf.constant([[10 , 10 , 0 ]], dtype=tf.float32) print_scaled_dot_product_attention(temp_q3, temp_k, temp_v)
Attention weights are:
tf.Tensor([[0.5 0.5 0. 0. ]], shape=(1, 4), dtype=float32)
Output is:
tf.Tensor([[5.5 0. ]], shape=(1, 2), dtype=float32)1 2 3 temp_q4 = tf.constant([[0 , 10 , 0 ], [0 , 0 , 10 ], [10 , 10 , 0 ]], dtype=tf.float32) print_scaled_dot_product_attention(temp_q4, temp_k, temp_v)
Attention weights are:
tf.Tensor(
[[0. 1. 0. 0. ]
[0. 0. 0.5 0.5]
[0.5 0.5 0. 0. ]], shape=(3, 4), dtype=float32)
Output is:
tf.Tensor(
[[ 10. 0. ]
[550. 5.5]
[ 5.5 0. ]], shape=(3, 2), dtype=float32)1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 class MultiHeadAttention (keras.layers.Layer) : """ 理论上: x -> Wq0 -> q0 x -> Wk0 -> k0 x -> Wv0 -> v0 不同场景下q, k, v不一定是相同的: - 对于encoder或decoder中的self-attention而言,q, k, v相同,都是词向量或下层encoder或decoder的输出 - 而对于encoder-decoder之间的attention而言,k, v相同,但是q不一定相同。 故实战中: q -> Wq0 -> q0 k -> Wk0 -> k0 v -> Wv0 -> v0 实战中技巧: 为实现多头注意力机制,需要使用q同Wq0, Wq1, ... 分别相乘得到q0, q1, ... k, v也类似,然后做缩放点积注意力,进行拼接送往feed-forword 实战中使用q 与一个大的Wq做矩阵乘法,然后分割,做后续工作。原理为分块矩阵的乘法。k, v类似。 优点:运算更为密集,代码更为简洁 q -> Wq -> Q -> split ->q0, q1, q2 ... """ def __init__ (self, d_model, num_heads) : """ Args: d_model: 模型维度, d_model = num_heads * depth(q或k或v的长度) num_heads: 多头注意力的头数 """ super(MultiHeadAttention, self).__init__() self.num_heads = num_heads self.d_model = d_model assert self.d_model % self.num_heads == 0 self.depth = self.d_model // self.num_heads self.WQ = keras.layers.Dense(self.d_model) self.WK = keras.layers.Dense(self.d_model) self.WV = keras.layers.Dense(self.d_model) self.dense = keras.layers.Dense(self.d_model) def split_heads (self, x, batch_size) : x = tf.reshape(x, (batch_size, -1 , self.num_heads, self.depth)) return tf.transpose(x, perm=[0 , 2 , 1 , 3 ]) def call (self, q, k, v, mask) : batch_size = tf.shape(q)[0 ] q = self.WQ(q) k = self.WK(k) v = self.WV(v) q = self.split_heads(q, batch_size) k = self.split_heads(k, batch_size) v = self.split_heads(v, batch_size) scaled_attention_outputs, attention_weights = scaled_dot_product_attention( q, k, v, mask) scaled_attention_outputs = tf.transpose(scaled_attention_outputs, perm=[0 , 2 , 1 , 3 ]) concat_attention = tf.reshape(scaled_attention_outputs, ( batch_size, -1 , self.d_model, )) output = self.dense(concat_attention) return output, attention_weights temp_mha = MultiHeadAttention(d_model=512 , num_heads=8 ) y = tf.random.uniform((1 , 60 , 256 )) output, attn = temp_mha(y, y, y, mask=None ) print(output.shape) print(attn.shape)
(1, 60, 512)
(1, 8, 60, 60)1 2 3 4 5 6 7 8 9 10 def feed_forword_network (d_model, dff) : return keras.Sequential([ keras.layers.Dense(dff, activation='relu' ), keras.layers.Dense(d_model) ]) sample_ffn = feed_forword_network(512 , 2048 ) sample_ffn(tf.random.uniform((64 , 50 , 512 ))).shape
TensorShape([64, 50, 512])1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 class EncoderLayer (keras.layers.Layer) : """ x -> self attention -> add & normalize & dropout -> out1 out1 -> ffn ->add & normalize & dropout -> out2 """ def __init__ (self, d_model, num_heads, dff, rate=0.1 ) : """ Args: - d_model: self-attention 和 feed_forword_network使用 - num_heads: self-attention使用 - dff: feed_forword_network使用 - rate: 默认值0.1, dropout使用 """ super(EncoderLayer, self).__init__() self.mha = MultiHeadAttention(d_model, num_heads) self.ffn = feed_forword_network(d_model, dff) self.layer_norm1 = keras.layers.LayerNormalization(epsilon=1e-6 ) self.layer_norm2 = keras.layers.LayerNormalization(epsilon=1e-6 ) self.dropout1 = keras.layers.Dropout(rate) self.dropout2 = keras.layers.Dropout(rate) def call (self, x, training, encoder_padding_mask) : attn_output, _ = self.mha(x, x, x, encoder_padding_mask) attn_output = self.dropout1(attn_output, training=training) out1 = self.layer_norm1(x + attn_output) ffn_output = self.ffn(out1) ffn_output = self.dropout2(ffn_output, training) out2 = self.layer_norm2(out1 + ffn_output) return out2 sample_encoder_layer = EncoderLayer(512 , 8 , 2048 ) sample_input = tf.random.uniform((64 , 50 , 512 )) sample_output = sample_encoder_layer(sample_input, False , None ) print(sample_output.shape)
(64, 50, 512)1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 class DecoderLayer (keras.layers.Layer) : """ x -> self attention -> add & normlize & dropout -> out1 out1, encoding_outputs -> attention -> add & normalize & dropout -> out2 out2 -> ffn -> add & normalize & dropout -> out3 """ def __init__ (self, d_model, num_heads, dff, rate=0.1 ) : """ Args: - d_model: DecoderLayer输出的最后一维的长度 - num_heads: 头数 - dff: dim of feed_forword_network - rate=0.1: the frequence of dropout during training time. """ super(DecoderLayer, self).__init__() self.mha1 = MultiHeadAttention(d_model, num_heads) self.mha2 = MultiHeadAttention(d_model, num_heads) self.ffn = feed_forword_network(d_model, dff) self.layer_norm1 = keras.layers.LayerNormalization(epsilon=1e-6 ) self.layer_norm2 = keras.layers.LayerNormalization(epsilon=1e-6 ) self.layer_norm3 = keras.layers.LayerNormalization(epsilon=1e-6 ) self.dropout1 = keras.layers.Dropout(rate) self.dropout2 = keras.layers.Dropout(rate) self.dropout3 = keras.layers.Dropout(rate) def call (self, x, encoding_outputs, training, decoder_mask, encoder_decoder_padding_mask) : """ Args: - x: input - encoding_output: - training: - decoder_mask: 由look_ahead_mask和decoder_padding_mask取或得到的,意为 对decoder的输入中的每一个单词来说,不应该注意到其后面的单词 也不能注意到其前面的padding的单词 - encoder_decoder_padding_mask: 对于decoder中的某一隐含状态而言,不用注意到 encoder的输入的padding的部分。 """ attn1, attn_weights1 = self.mha1(x, x, x, decoder_mask) attn1 = self.dropout1(attn1, training=training) out1 = self.layer_norm1(attn1 + x) attn2, attn_weights2 = self.mha2(out1, encoding_outputs, encoding_outputs, encoder_decoder_padding_mask) attn2 = self.dropout2(attn2, training=training) out2 = self.layer_norm2(attn2 + x) ffn_output = self.ffn(out2) ffn_output = self.dropout3(ffn_output, training=training) out3 = self.layer_norm3(ffn_output + out2) return out3, attn_weights1, attn_weights2 sample_decoder_layer = DecoderLayer(512 , 8 , 2048 ) sample_decoder_input = tf.random.uniform((64 , 60 , 512 )) sample_decoder_output, sample_decoder_attn_weights1, sample_decoder_attn_weights2 = sample_decoder_layer( sample_decoder_input, sample_output, False , None , None ) print(sample_decoder_output.shape) print(sample_decoder_attn_weights1.shape) print(sample_decoder_attn_weights2.shape)
(64, 60, 512)
(64, 8, 60, 60)
(64, 8, 60, 50)1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 class EncoderModel (keras.layers.Layer) : def __init__ (self, num_layers, input_vocab_size, max_length, d_model, num_heads, dff, rate=0.1 ) : """ Args: num_layers: EncoderModel中EncoderLayer的层数 input_vocab_size: 做词嵌入的embedding层使用,为方便底层输出作为高层输入,embedding_dim与 d_model相同。 max_length: get_position_embedding使用 d_model: EncoderLayer层输出的最后轴的长度,或者说每个单词经过多头注意力计算后的长度 num_heads: 多头数 dff: dim of feed forword network rate=0.1: the rate of dropout """ super(EncoderModel, self).__init__() self.d_model = d_model self.num_layers = num_layers self.max_length = max_length self.embedding = keras.layers.Embedding(input_vocab_size, d_model) self.position_embedding = get_position_embedding( max_length, self.d_model) self.dropout = keras.layers.Dropout(rate) self.encoder_layers = [ EncoderLayer(d_model, num_heads, dff, rate) for _ in range(self.num_layers) ] def call (self, x, training, encoder_padding_mask) : """ Args: x: training: dropout使用 mask: """ input_seq_len = tf.shape(x)[1 ] tf.debugging.assert_less_equal( input_seq_len, self.max_length, "input_seq_len should be less or equal to self.max_length" ) x = self.embedding(x) x *= tf.math.sqrt(tf.cast(self.d_model, tf.float32)) x += self.position_embedding[:, :input_seq_len, :] x = self.dropout(x, training=training) for i in range(self.num_layers): x = self.encoder_layers[i](x, training, encoder_padding_mask) return x sample_encoder_model = EncoderModel(2 , 8500 , max_length, 512 , 8 , 2048 ) sample_encoder_model_input = tf.random.uniform((64 , 37 )) sample_encoder_model_output = sample_encoder_model(sample_encoder_model_input, False , encoder_padding_mask=None ) print(sample_encoder_model_output.shape)
(64, 37, 512)1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 class DecoderModel (keras.layers.Layer) : def __init__ (self, num_layers, target_vocab_size, max_length, d_model, num_heads, dff, rate=0.1 ) : super(DecoderModel, self).__init__() self.num_layers = num_layers self.max_length = max_length self.d_model = d_model self.embedding = keras.layers.Embedding(target_vocab_size, self.d_model) self.position_embedding = get_position_embedding( self.max_length, self.d_model) self.dropout = keras.layers.Dropout(rate) self.decoder_layers = [ DecoderLayer(d_model, num_heads, dff, rate) for _ in range(self.num_layers) ] def call (self, x, encoding_outputs, training, decoder_mask, encoder_decoder_padding_mask) : output_seq_len = tf.shape(x)[1 ] tf.debugging.assert_less_equal( output_seq_len, self.max_length, "output_seq_len should be less or equal to self.max_length" ) attention_weights = {} x = self.embedding(x) x *= tf.math.sqrt(tf.cast(self.d_model, tf.float32)) x += self.position_embedding[:, :output_seq_len, :] x = self.dropout(x, training=training) for i in range(self.num_layers): x, attn1, attn2 = self.decoder_layers[i]( x, encoding_outputs, training, decoder_mask, encoder_decoder_padding_mask) attention_weights['decoder_layer{}_att1' .format(i + 1 )] = attn1 attention_weights['decoder_layer{}_att2' .format(i + 1 )] = attn2 return x, attention_weights sample_decoder_model = DecoderModel(2 , 80000 , max_length, 512 , 8 , 2048 ) sample_decoder_model_input = tf.random.uniform((64 , 35 )) sample_decoder_model_output, sample_decoder_model_att = sample_decoder_model( sample_decoder_model_input, sample_encoder_model_output, training=False , decoder_mask=None , encoder_decoder_padding_mask=None ) print(sample_decoder_model_output.shape) for key in sample_decoder_model_att: print(key, sample_decoder_model_att[key].shape)
(64, 35, 512)
decoder_layer1_att1 (64, 8, 35, 35)
decoder_layer1_att2 (64, 8, 35, 37)
decoder_layer2_att1 (64, 8, 35, 35)
decoder_layer2_att2 (64, 8, 35, 37)1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 class Transformer (keras.Model) : def __init__ (self, num_layers, input_vocab_size, target_vocab_size, max_length, d_model, num_heads, dff, rate=0.1 ) : """ Args: num_layers: 本模型中Encoder和Decoder中的层数相同,故此处不做区分。 input_vocab_size: 输入词表大小 target_vocab_size: 目标词表大小 max_length: 序列最大长度 d_model: d_model = embedding_dim num_heads: 多头数 dff: dim of feed forword network rate=0.1: the rate of dropout """ super(Transformer, self).__init__() self.encoder_model = EncoderModel(num_layers, input_vocab_size, max_length, d_model, num_heads, dff, rate) self.decoder_model = DecoderModel(num_layers, target_vocab_size, max_length, d_model, num_heads, dff, rate) self.final_layer = keras.layers.Dense(target_vocab_size) def call (self, inp, tar, training, encoder_padding_mask, decoder_mask, encoder_decoder_padding_mask) : encoding_outputs = self.encoder_model(inp, training, encoder_padding_mask) decoding_outputs, attention_weights = self.decoder_model( tar, encoding_outputs, training, decoder_mask, encoder_decoder_padding_mask) predictions = self.final_layer(decoding_outputs) return predictions, attention_weights sample_transformer = Transformer(2 , 8500 , 8000 , max_length, 512 , 8 , 2048 ) temp_input = tf.random.uniform((64 , 26 )) temp_target = tf.random.uniform((64 , 31 )) predictions, attention_weights = sample_transformer( temp_input, temp_target, training=False , encoder_padding_mask=None , decoder_mask=None , encoder_decoder_padding_mask=None ) print(predictions.shape) for key in attention_weights.keys(): print(key, attention_weights[key].shape)
(64, 31, 8000)
decoder_layer1_att1 (64, 8, 31, 31)
decoder_layer1_att2 (64, 8, 31, 26)
decoder_layer2_att1 (64, 8, 31, 31)
decoder_layer2_att2 (64, 8, 31, 26)1 2 3 4 5 6 7 8 9 10 11 12 num_layers = 4 d_model = 128 dff = 512 num_heads = 8 input_vocab_size = pt_tokenizer.vocab_size + 2 target_vocab_size = en_tokenizer.vocab_size + 2 dropout_rate = 0.1 transformer = Transformer(num_layers, input_vocab_size, target_vocab_size, max_length, d_model, num_heads, dff, dropout_rate)
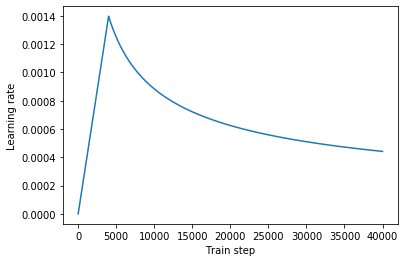
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class CustomizedSchedule (keras.optimizers.schedules.LearningRateSchedule) : def __init__ (self, d_model, warmup_steps=4000 ) : super(CustomizedSchedule, self).__init__() self.d_model = tf.cast(d_model, tf.float32) self.warmup_steps = warmup_steps def __call__ (self, step) : arg1 = tf.math.rsqrt(step) arg2 = step * (self.warmup_steps**(-1.5 )) arg3 = tf.math.rsqrt(self.d_model) return arg3 * tf.math.minimum(arg1, arg2) learning_rate = CustomizedSchedule(d_model) optimizer = keras.optimizers.Adam(learning_rate=learning_rate, beta_1=0.9 , beta_2=0.98 , epsilon=1e-9 )
1 2 3 4 5 temp_learning_rate_schedule = CustomizedSchedule(d_model) plt.plot(temp_learning_rate_schedule(tf.range(40000 , dtype=tf.float32))) plt.ylabel('Learning rate' ) plt.xlabel('Train step' )
Text(0.5, 0, 'Train step')
1 2 3 4 5 6 7 8 9 10 11 loss_object = keras.losses.SparseCategoricalCrossentropy(from_logits=True , reduction='none' ) def loss_function (real, pred) : mask = tf.math.logical_not(tf.math.equal(real, 0 )) loss_ = loss_object(real, pred) mask = tf.cast(mask, dtype=loss_.dtype) loss_ *= mask return tf.reduce_mean(loss_)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 def create_masks (inp, tar) : """ 为数据集中的每条数据都创建所需要的mask, 对每条数据, 其训练过程中的mask为: Encoder: - encoder_padding_mask: train sequence中padding的部分不需要做attention. 作用在:self attention of EncoderLayer Decoder: - decoder_padding_mask: target sequence中padding的部分不需要做attention. 作用在:self attention of DecoderLayer - look_ahead_mask: 训练过程中,target sequence中对某一单词做attention时, 不能计算其与其后面单词的注意力分数。 作用在:self attention of DecoderLayer - encoder_decoder_padding_mask: decoder中某一隐含状态需要与encoder_outputs中的每一个输出做attention, 但是对于encoder_outputs中存在padding项,对于padding的部分,无需计算 注意力。 作用在:encoder_decoder attention of DecoderLayer 其中decoder_padding_mask和look_ahead_mask作用在Decoder的同一层上,所以需要做与操作。 """ encoder_padding_mask = create_padding_mask(inp) encoder_decoder_padding_mask = create_padding_mask(inp) look_ahead_mask = create_look_ahead_mask(tf.shape(tar)[1 ]) decoder_padding_mask = create_padding_mask(tar) decoder_mask = tf.maximum(decoder_padding_mask, look_ahead_mask) return encoder_padding_mask, decoder_mask, encoder_decoder_padding_mask
1 temp_inp, temp_tar = iter(train_dataset.take(1 )).next()
1 2 3 print(temp_inp.shape) print(temp_tar.shape) create_masks(temp_inp, temp_tar)
(64, 38)
(64, 40)
(<tf.Tensor: shape=(64, 1, 1, 38), dtype=float32, numpy=
array([[[[0., 0., 0., ..., 1., 1., 1.]]],
[[[0., 0., 0., ..., 1., 1., 1.]]],
[[[0., 0., 0., ..., 1., 1., 1.]]],
...,
[[[0., 0., 0., ..., 1., 1., 1.]]],
[[[0., 0., 0., ..., 1., 1., 1.]]],
[[[0., 0., 0., ..., 1., 1., 1.]]]], dtype=float32)>,
<tf.Tensor: shape=(64, 1, 40, 40), dtype=float32, numpy=
array([[[[0., 1., 1., ..., 1., 1., 1.],
[0., 0., 1., ..., 1., 1., 1.],
[0., 0., 0., ..., 1., 1., 1.],
...,
[0., 0., 0., ..., 1., 1., 1.],
[0., 0., 0., ..., 1., 1., 1.],
[0., 0., 0., ..., 1., 1., 1.]]],
[[[0., 1., 1., ..., 1., 1., 1.],
[0., 0., 1., ..., 1., 1., 1.],
[0., 0., 0., ..., 1., 1., 1.],
...,
[0., 0., 0., ..., 1., 1., 1.],
[0., 0., 0., ..., 1., 1., 1.],
[0., 0., 0., ..., 1., 1., 1.]]],
[[[0., 1., 1., ..., 1., 1., 1.],
[0., 0., 1., ..., 1., 1., 1.],
[0., 0., 0., ..., 1., 1., 1.],
...,
[0., 0., 0., ..., 1., 1., 1.],
[0., 0., 0., ..., 1., 1., 1.],
[0., 0., 0., ..., 1., 1., 1.]]],
...,
[[[0., 1., 1., ..., 1., 1., 1.],
[0., 0., 1., ..., 1., 1., 1.],
[0., 0., 0., ..., 1., 1., 1.],
...,
[0., 0., 0., ..., 1., 1., 1.],
[0., 0., 0., ..., 1., 1., 1.],
[0., 0., 0., ..., 1., 1., 1.]]],
[[[0., 1., 1., ..., 1., 1., 1.],
[0., 0., 1., ..., 1., 1., 1.],
[0., 0., 0., ..., 1., 1., 1.],
...,
[0., 0., 0., ..., 1., 1., 1.],
[0., 0., 0., ..., 1., 1., 1.],
[0., 0., 0., ..., 1., 1., 1.]]],
[[[0., 1., 1., ..., 1., 1., 1.],
[0., 0., 1., ..., 1., 1., 1.],
[0., 0., 0., ..., 1., 1., 1.],
...,
[0., 0., 0., ..., 1., 1., 1.],
[0., 0., 0., ..., 1., 1., 1.],
[0., 0., 0., ..., 1., 1., 1.]]]], dtype=float32)>,
<tf.Tensor: shape=(64, 1, 1, 38), dtype=float32, numpy=
array([[[[0., 0., 0., ..., 1., 1., 1.]]],
[[[0., 0., 0., ..., 1., 1., 1.]]],
[[[0., 0., 0., ..., 1., 1., 1.]]],
...,
[[[0., 0., 0., ..., 1., 1., 1.]]],
[[[0., 0., 0., ..., 1., 1., 1.]]],
[[[0., 0., 0., ..., 1., 1., 1.]]]], dtype=float32)>)1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 """ train_loss: 以batch为单位,累加每个batch上的loss,并求平均, 故train_loss单位为 loss/batch train_accuracy: 同上,每个batch上的准确率 这两个指标只用于显示,并不参与训练 """ train_loss = keras.metrics.Mean(name='train_loss' ) train_accuracy = keras.metrics.SparseCategoricalAccuracy(name='train_accuracy' ) train_step_signature = [ tf.TensorSpec(shape=(None , None ), dtype=tf.int64), tf.TensorSpec(shape=(None , None ), dtype=tf.int64), ] @tf.function(input_signature=train_step_signature) def train_step (inp, tar) : tar_inp = tar[:, :-1 ] tar_real = tar[:, 1 :] encoder_padding_mask, decoder_mask, encoder_decoder_padding_mask = create_masks( inp, tar_inp) with tf.GradientTape() as tape: predictions, _ = transformer(inp, tar_inp, True , encoder_padding_mask, decoder_mask, encoder_decoder_padding_mask) loss = loss_function(tar_real, predictions) gradients = tape.gradient(loss, transformer.trainable_variables) optimizer.apply_gradients(zip(gradients, transformer.trainable_variables)) train_loss(loss) train_accuracy(tar_real, predictions) epochs = 20 for epoch in range(epochs): start = time.time() train_loss.reset_states() train_accuracy.reset_states() for (batch, (inp, tar)) in enumerate(train_dataset): train_step(inp, tar) if batch % 100 == 0 : print('Epoch {} Batch {} Loss {:.4f} Accuracy {:.4f}' .format( epoch + 1 , batch, train_loss.result(), train_accuracy.result())) print('Epoch {} Loss {:.4f} Accuracy {:.4f}' .format( epoch + 1 , train_loss.result(), train_accuracy.result())) print('Time take for 1 epoch: {} secs\n' .format(time.time() - start))
Epoch 1 Batch 0 Loss 4.4194 Accuracy 0.0000
Epoch 1 Batch 100 Loss 4.1633 Accuracy 0.0149
Epoch 1 Batch 200 Loss 4.0548 Accuracy 0.0244
Epoch 1 Batch 300 Loss 3.9067 Accuracy 0.0340
Epoch 1 Batch 400 Loss 3.7226 Accuracy 0.0411
Epoch 1 Batch 500 Loss 3.5698 Accuracy 0.0487
Epoch 1 Batch 600 Loss 3.4341 Accuracy 0.0567
Epoch 1 Batch 700 Loss 3.3126 Accuracy 0.0638
Epoch 1 Loss 3.3109 Accuracy 0.0639
Time take for 1 epoch: 1501.406435251236 secs
Epoch 2 Batch 0 Loss 2.6902 Accuracy 0.1150
Epoch 2 Batch 100 Loss 2.4438 Accuracy 0.1159
Epoch 2 Batch 200 Loss 2.4002 Accuracy 0.1185
Epoch 2 Batch 300 Loss 2.3858 Accuracy 0.1214
Epoch 2 Batch 400 Loss 2.3656 Accuracy 0.1235
Epoch 2 Batch 500 Loss 2.3478 Accuracy 0.1259
Epoch 2 Batch 600 Loss 2.3378 Accuracy 0.1282
Epoch 2 Batch 700 Loss 2.3176 Accuracy 0.1299
Epoch 2 Loss 2.3172 Accuracy 0.1300
Time take for 1 epoch: 1429.5275447368622 secs
Epoch 3 Batch 0 Loss 1.9690 Accuracy 0.1397
Epoch 3 Batch 100 Loss 2.1808 Accuracy 0.1452
Epoch 3 Batch 200 Loss 2.1403 Accuracy 0.1460
Epoch 3 Batch 300 Loss 2.1247 Accuracy 0.1468
Epoch 3 Batch 400 Loss 2.1144 Accuracy 0.1487
Epoch 3 Batch 500 Loss 2.1014 Accuracy 0.1509
Epoch 3 Batch 600 Loss 2.0871 Accuracy 0.1523
Epoch 3 Batch 700 Loss 2.0773 Accuracy 0.1539
Epoch 3 Loss 2.0777 Accuracy 0.1540
Time take for 1 epoch: 1483.9826645851135 secs
Epoch 4 Batch 0 Loss 1.7831 Accuracy 0.1558
Epoch 4 Batch 100 Loss 1.9128 Accuracy 0.1655
Epoch 4 Batch 200 Loss 1.9072 Accuracy 0.1687
Epoch 4 Batch 300 Loss 1.9042 Accuracy 0.1710
Epoch 4 Batch 400 Loss 1.8887 Accuracy 0.1733
Epoch 4 Batch 500 Loss 1.8748 Accuracy 0.1760
Epoch 4 Batch 600 Loss 1.8588 Accuracy 0.1775
Epoch 4 Batch 700 Loss 1.8479 Accuracy 0.1794
Epoch 4 Loss 1.8480 Accuracy 0.1795
Time take for 1 epoch: 1414.8520936965942 secs
Epoch 5 Batch 0 Loss 1.9223 Accuracy 0.2226
Epoch 5 Batch 100 Loss 1.6692 Accuracy 0.1978
Epoch 5 Batch 200 Loss 1.6727 Accuracy 0.1992
Epoch 5 Batch 300 Loss 1.6637 Accuracy 0.2002
Epoch 5 Batch 400 Loss 1.6577 Accuracy 0.2014
Epoch 5 Batch 500 Loss 1.6493 Accuracy 0.2028
Epoch 5 Batch 600 Loss 1.6436 Accuracy 0.2040
Epoch 5 Batch 700 Loss 1.6349 Accuracy 0.2055
Epoch 5 Loss 1.6348 Accuracy 0.2055
Time take for 1 epoch: 1422.2958707809448 secs
Epoch 6 Batch 0 Loss 1.2876 Accuracy 0.2011
Epoch 6 Batch 100 Loss 1.4666 Accuracy 0.2197
Epoch 6 Batch 200 Loss 1.4627 Accuracy 0.2199
Epoch 6 Batch 300 Loss 1.4615 Accuracy 0.2208
Epoch 6 Batch 400 Loss 1.4583 Accuracy 0.2220
Epoch 6 Batch 500 Loss 1.4565 Accuracy 0.2232
Epoch 6 Batch 600 Loss 1.4501 Accuracy 0.2246
Epoch 6 Batch 700 Loss 1.4461 Accuracy 0.2253
Epoch 6 Loss 1.4468 Accuracy 0.2253
Time take for 1 epoch: 1420.1133754253387 secs
Epoch 7 Batch 0 Loss 1.3153 Accuracy 0.2366
Epoch 7 Batch 100 Loss 1.2860 Accuracy 0.2414
Epoch 7 Batch 200 Loss 1.2790 Accuracy 0.2425
Epoch 7 Batch 300 Loss 1.2829 Accuracy 0.2423
Epoch 7 Batch 400 Loss 1.2750 Accuracy 0.2428
Epoch 7 Batch 500 Loss 1.2714 Accuracy 0.2442
Epoch 7 Batch 600 Loss 1.2688 Accuracy 0.2451
Epoch 7 Batch 700 Loss 1.2657 Accuracy 0.2461
Epoch 7 Loss 1.2660 Accuracy 0.2461
Time take for 1 epoch: 1420.649710893631 secs
Epoch 8 Batch 0 Loss 1.2569 Accuracy 0.2747
Epoch 8 Batch 100 Loss 1.1093 Accuracy 0.2616
Epoch 8 Batch 200 Loss 1.1140 Accuracy 0.2602
Epoch 8 Batch 300 Loss 1.1138 Accuracy 0.2614
Epoch 8 Batch 400 Loss 1.1136 Accuracy 0.2615
Epoch 8 Batch 500 Loss 1.1169 Accuracy 0.2625
Epoch 8 Batch 600 Loss 1.1161 Accuracy 0.2631
Epoch 8 Batch 700 Loss 1.1150 Accuracy 0.2631
Epoch 8 Loss 1.1150 Accuracy 0.2632
Time take for 1 epoch: 1430.6083216667175 secs
Epoch 9 Batch 0 Loss 1.1143 Accuracy 0.2859
Epoch 9 Batch 100 Loss 0.9854 Accuracy 0.2775
Epoch 9 Batch 200 Loss 0.9909 Accuracy 0.2768
Epoch 9 Batch 300 Loss 0.9948 Accuracy 0.2764
Epoch 9 Batch 400 Loss 0.9964 Accuracy 0.2772
Epoch 9 Batch 500 Loss 1.0010 Accuracy 0.2775
Epoch 9 Batch 600 Loss 1.0054 Accuracy 0.2775
Epoch 9 Batch 700 Loss 1.0064 Accuracy 0.2770
Epoch 9 Loss 1.0063 Accuracy 0.2770
Time take for 1 epoch: 1493.6901807785034 secs
Epoch 10 Batch 0 Loss 0.7144 Accuracy 0.2776
Epoch 10 Batch 100 Loss 0.9023 Accuracy 0.2917
Epoch 10 Batch 200 Loss 0.9075 Accuracy 0.2905
Epoch 10 Batch 300 Loss 0.9116 Accuracy 0.2902
Epoch 10 Batch 400 Loss 0.9148 Accuracy 0.2899
Epoch 10 Batch 500 Loss 0.9150 Accuracy 0.2891
Epoch 10 Batch 600 Loss 0.9188 Accuracy 0.2879
Epoch 10 Batch 700 Loss 0.9220 Accuracy 0.2873
Epoch 10 Loss 0.9223 Accuracy 0.2874
Time take for 1 epoch: 1462.3251810073853 secs
Epoch 11 Batch 0 Loss 0.8465 Accuracy 0.3057
Epoch 11 Batch 100 Loss 0.8375 Accuracy 0.3001
Epoch 11 Batch 200 Loss 0.8420 Accuracy 0.2995
Epoch 11 Batch 300 Loss 0.8453 Accuracy 0.2983
Epoch 11 Batch 400 Loss 0.8488 Accuracy 0.2982
Epoch 11 Batch 500 Loss 0.8516 Accuracy 0.2973
Epoch 11 Batch 600 Loss 0.8565 Accuracy 0.2969
Epoch 11 Batch 700 Loss 0.8601 Accuracy 0.2970
Epoch 11 Loss 0.8600 Accuracy 0.2970
Time take for 1 epoch: 1454.8198113441467 secs
Epoch 12 Batch 0 Loss 0.7785 Accuracy 0.2861
Epoch 12 Batch 100 Loss 0.7620 Accuracy 0.3063
Epoch 12 Batch 200 Loss 0.7725 Accuracy 0.3071
Epoch 12 Batch 300 Loss 0.7835 Accuracy 0.3074
Epoch 12 Batch 400 Loss 0.7905 Accuracy 0.3061
Epoch 12 Batch 500 Loss 0.7961 Accuracy 0.3056
Epoch 12 Batch 600 Loss 0.8003 Accuracy 0.3046
Epoch 12 Batch 700 Loss 0.8052 Accuracy 0.3035
Epoch 12 Loss 0.8053 Accuracy 0.3035
Time take for 1 epoch: 1453.3642852306366 secs
Epoch 13 Batch 0 Loss 0.7461 Accuracy 0.3647
Epoch 13 Batch 100 Loss 0.7159 Accuracy 0.3162
Epoch 13 Batch 200 Loss 0.7337 Accuracy 0.3148
Epoch 13 Batch 300 Loss 0.7365 Accuracy 0.3127
Epoch 13 Batch 400 Loss 0.7432 Accuracy 0.3118
Epoch 13 Batch 500 Loss 0.7519 Accuracy 0.3114
Epoch 13 Batch 600 Loss 0.7568 Accuracy 0.3112
Epoch 13 Batch 700 Loss 0.7621 Accuracy 0.3106
Epoch 13 Loss 0.7622 Accuracy 0.3106
Time take for 1 epoch: 1441.3918175697327 secs
Epoch 14 Batch 0 Loss 0.6012 Accuracy 0.2895
Epoch 14 Batch 100 Loss 0.6744 Accuracy 0.3177
Epoch 14 Batch 200 Loss 0.6891 Accuracy 0.3176
Epoch 14 Batch 300 Loss 0.6982 Accuracy 0.3173
Epoch 14 Batch 400 Loss 0.7026 Accuracy 0.3169
Epoch 14 Batch 500 Loss 0.7077 Accuracy 0.3166
Epoch 14 Batch 600 Loss 0.7160 Accuracy 0.3160
Epoch 14 Batch 700 Loss 0.7221 Accuracy 0.3154
Epoch 14 Loss 0.7222 Accuracy 0.3154
Time take for 1 epoch: 1430.102513551712 secs
Epoch 15 Batch 0 Loss 0.6714 Accuracy 0.3396
Epoch 15 Batch 100 Loss 0.6608 Accuracy 0.3265
Epoch 15 Batch 200 Loss 0.6589 Accuracy 0.3235
Epoch 15 Batch 300 Loss 0.6670 Accuracy 0.3233
Epoch 15 Batch 400 Loss 0.6751 Accuracy 0.3239
Epoch 15 Batch 500 Loss 0.6792 Accuracy 0.3233
Epoch 15 Batch 600 Loss 0.6864 Accuracy 0.3225
Epoch 15 Batch 700 Loss 0.6911 Accuracy 0.3218
Epoch 15 Loss 0.6908 Accuracy 0.3217
Time take for 1 epoch: 1489.9207346439362 secs
Epoch 16 Batch 0 Loss 0.6183 Accuracy 0.3633
Epoch 16 Batch 100 Loss 0.6202 Accuracy 0.3317
Epoch 16 Batch 200 Loss 0.6296 Accuracy 0.3298
Epoch 16 Batch 300 Loss 0.6352 Accuracy 0.3278
Epoch 16 Batch 400 Loss 0.6417 Accuracy 0.3274
Epoch 16 Batch 500 Loss 0.6475 Accuracy 0.3275
Epoch 16 Batch 600 Loss 0.6530 Accuracy 0.3265
Epoch 16 Batch 700 Loss 0.6580 Accuracy 0.3256
Epoch 16 Loss 0.6584 Accuracy 0.3256
Time take for 1 epoch: 1519.223790884018 secs
Epoch 17 Batch 0 Loss 0.7199 Accuracy 0.4098
Epoch 17 Batch 100 Loss 0.5992 Accuracy 0.3378
Epoch 17 Batch 200 Loss 0.6053 Accuracy 0.3334
Epoch 17 Batch 300 Loss 0.6103 Accuracy 0.3326
Epoch 17 Batch 400 Loss 0.6161 Accuracy 0.3319
Epoch 17 Batch 500 Loss 0.6229 Accuracy 0.3311
Epoch 17 Batch 600 Loss 0.6277 Accuracy 0.3307
Epoch 17 Batch 700 Loss 0.6328 Accuracy 0.3294
Epoch 17 Loss 0.6329 Accuracy 0.3294
Time take for 1 epoch: 1485.4576337337494 secs
Epoch 18 Batch 0 Loss 0.5724 Accuracy 0.3220
Epoch 18 Batch 100 Loss 0.5764 Accuracy 0.3363
Epoch 18 Batch 200 Loss 0.5827 Accuracy 0.3374
Epoch 18 Batch 300 Loss 0.5891 Accuracy 0.3371
Epoch 18 Batch 400 Loss 0.5941 Accuracy 0.3355
Epoch 18 Batch 500 Loss 0.5995 Accuracy 0.3344
Epoch 18 Batch 600 Loss 0.6040 Accuracy 0.3338
Epoch 18 Batch 700 Loss 0.6088 Accuracy 0.3330
Epoch 18 Loss 0.6088 Accuracy 0.3330
Time take for 1 epoch: 1476.7011284828186 secs
Epoch 19 Batch 0 Loss 0.6577 Accuracy 0.3546
Epoch 19 Batch 100 Loss 0.5437 Accuracy 0.3411
Epoch 19 Batch 200 Loss 0.5607 Accuracy 0.3421
Epoch 19 Batch 300 Loss 0.5657 Accuracy 0.3400
Epoch 19 Batch 400 Loss 0.5704 Accuracy 0.3390
Epoch 19 Batch 500 Loss 0.5762 Accuracy 0.3380
Epoch 19 Batch 600 Loss 0.5821 Accuracy 0.3377
Epoch 19 Batch 700 Loss 0.5876 Accuracy 0.3369
Epoch 19 Loss 0.5879 Accuracy 0.3369
Time take for 1 epoch: 1414.2364287376404 secs
Epoch 20 Batch 0 Loss 0.5179 Accuracy 0.3113
Epoch 20 Batch 100 Loss 0.5314 Accuracy 0.3440
Epoch 20 Batch 200 Loss 0.5418 Accuracy 0.3428
Epoch 20 Batch 300 Loss 0.5487 Accuracy 0.3432
Epoch 20 Batch 400 Loss 0.5541 Accuracy 0.3428
Epoch 20 Batch 500 Loss 0.5569 Accuracy 0.3416
Epoch 20 Batch 600 Loss 0.5633 Accuracy 0.3409
Epoch 20 Batch 700 Loss 0.5690 Accuracy 0.3402
Epoch 20 Loss 0.5690 Accuracy 0.3402
Time take for 1 epoch: 1407.2577855587006 secs1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 """ e.g: A B C D -> E F G H Train: A B C D, E F G -> F G H 训练过程中希望,模型输入为A B C D, E 时, 预测出F 模型输入为A B C D, E F 时, 预测出G 模型输入为A B C D, E F G时,预测出H 因为训练的过程中种有look_ahead_mask保证,所以矩阵同时输入。 Eval: A B C D, -> E A B C D, E -> F A B C D, E F -> G A B C D, E F G -> H """ def evaluate (inp_sentence) : input_id_sentence = [ pt_tokenizer.vocab_size ] + pt_tokenizer.encode(inp_sentence) + [pt_tokenizer.vocab_size + 1 ] encoder_input = tf.expand_dims(input_id_sentence, 0 ) decoder_input = tf.expand_dims([en_tokenizer.vocab_size], 0 ) for i in range(max_length): encoder_padding_mask, decoder_mask, encoder_decoder_padding_mask = create_masks( encoder_input, decoder_input) predictions, attention_weights = transformer( encoder_input, decoder_input, False , encoder_padding_mask, decoder_mask, encoder_decoder_padding_mask) predictions = predictions[:, -1 , :] predicted_id = tf.cast(tf.argmax(predictions, axis=-1 ), tf.int32) if tf.equal(predicted_id, en_tokenizer.vocab_size + 1 ): return tf.squeeze(decoder_input, axis=0 ), attention_weights decoder_input = tf.concat([decoder_input, [predicted_id]], axis=-1 ) return tf.sequeeze(decoder_input, axis=0 ), attention_weights
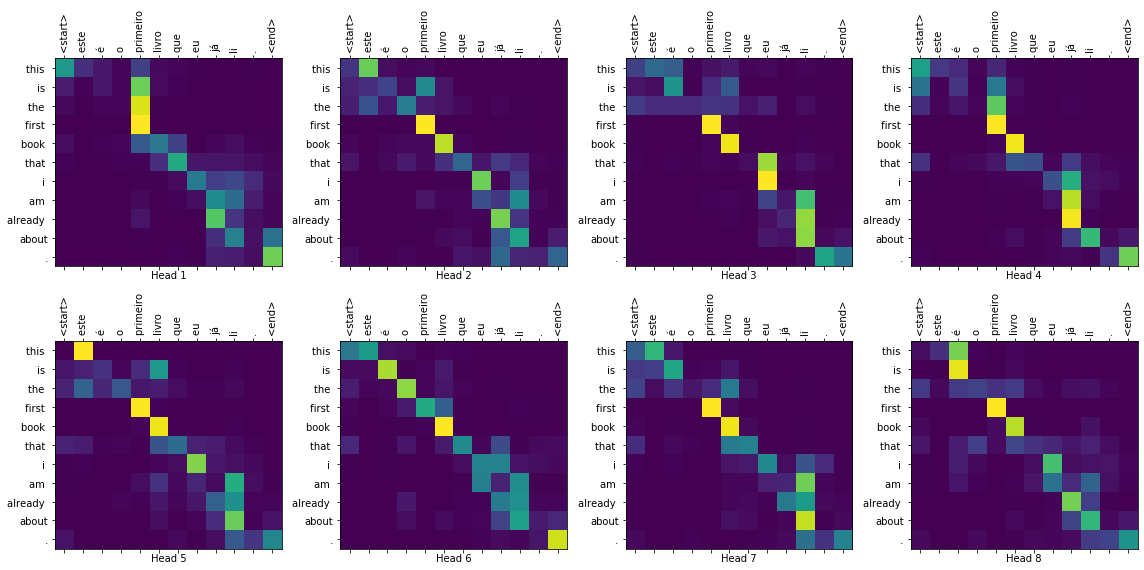
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 def plot_encoder_decoder_attention (attention, input_sentence, result, layer_name) : fig = plt.figure(figsize=(16 , 8 )) input_id_sentence = pt_tokenizer.encode(input_sentence) attention = tf.squeeze(attention[layer_name], axis=0 ) for head in range(attention.shape[0 ]): ax = fig.add_subplot(2 , 4 , head + 1 ) ax.matshow(attention[head][:-1 , :]) fontdict = {'fontsize' : 10 } ax.set_xticks(range(len(input_id_sentence) + 2 )) ax.set_yticks(range(len(result))) ax.set_ylim(len(result) - 1.5 , -0.5 ) ax.set_xticklabels( ['<start>' ] + [pt_tokenizer.decode([i]) for i in input_id_sentence] + ['<end>' ], fontdict=fontdict, rotation=90 ) ax.set_yticklabels([ en_tokenizer.decode([i]) for i in result if i < en_tokenizer.vocab_size ], fontdict=fontdict) ax.set_xlabel('Head {}' .format(head + 1 )) plt.tight_layout() plt.show()
1 2 3 4 5 6 7 8 9 10 11 def translate (input_sentence, layer_name='' ) : result, attention_weights = evaluate(input_sentence) predicted_sentence = en_tokenizer.decode( [i for i in result if i < en_tokenizer.vocab_size]) print("Input: {}" .format(input_sentence)) print("Predicted translation: {}" .format(predicted_sentence)) if layer_name: plot_encoder_decoder_attention(attention_weights, input_sentence, result, layer_name)
1 translate('está muito frio aqui.' )
Input: está muito frio aqui.
Predicted translation: it 's very coldly here , here 's all the way here of the u.s .1 translate('esta é a minha vida.' )
Input: esta é a minha vida.
Predicted translation: this is my life .1 translate('você ainda está em casa?' )
Input: você ainda está em casa?
Predicted translation: are you even home ?1 translate('este é o primeiro livro que eu já li.' , layer_name = 'decoder_layer4_att2' )
Input: este é o primeiro livro que eu já li.
Predicted translation: this is the first book that i am already about .
模型不够强大的原因
数据量小
模型未训练充分,只训练了20个epoch